
El Machine Learning es un campo de la inteligencia artificial que permite a las computadoras aprender y tomar decisiones sin estar programadas explícitamente. Utiliza algoritmos que analizan datos e identifican patrones, lo que permite a las máquinas mejorar el rendimiento según la experiencia. En lugar de seguir instrucciones específicas, la máquina aprende de datos anteriores, ajustando y mejorando su desempeño en tareas específicas. El objetivo es desarrollar sistemas capaces de generalizar el conocimiento y tomar decisiones autónomas basadas en la información disponible, que van desde la clasificación de datos hasta la predicción de resultados futuros.
Un «algoritmo» en el contexto del aprendizaje automático es un conjunto de instrucciones lógicas y matemáticas que permiten a una máquina aprender y tomar decisiones. Estos algoritmos procesan datos de entrada, reconocen patrones y ajustan su comportamiento sin intervención humana directa. Los algoritmos de aprendizaje automático pueden realizar tareas como clasificación, regresión, agrupación y reconocimiento de patrones. Su función es mejorar automáticamente a medida que están expuestas a más datos, lo que permite que las máquinas se adapten a diversas situaciones y tomen decisiones informadas. Esencialmente, los algoritmos son el núcleo de lo que impulsa el aprendizaje y la toma de decisiones en un entorno de aprendizaje automático.
Algoritmo KNN
El algoritmo KNN (K Nearest Neighbors) en el contexto del aprendizaje automático es un método de aprendizaje supervisado para clasificación y regresión. KNN se basa en la idea de que objetos similares están cerca en el espacio de características. En este algoritmo, se predice un nuevo punto considerando las etiquetas de los puntos «k» en el conjunto de datos de entrenamiento que están más cerca del nuevo punto.
Para la clasificación, KNN asigna la etiqueta más común entre los «k» vecinos más cercanos a un nuevo punto. En la regresión, los resultados de «k» vecinos se promedian para predecir un valor numérico.
El algoritmo KNN no requiere entrenamiento previo; simplemente recuerda el conjunto de datos de entrenamiento. Su flexibilidad y simplicidad lo hacen efectivo en situaciones donde la relación entre características y etiquetas no sigue un modelo matemático específico. Sin embargo, su rendimiento puede depender de la elección adecuada del valor «k» y de la métrica de distancia utilizada para medir la similitud entre puntos. En general, KNN destaca por su enfoque intuitivo y su capacidad para adaptarse a patrones de datos no lineales.
El siguiente código en Python utiliza la biblioteca matplotlib para crear un gráfico de dispersión y visualizar un conjunto de datos bidimensional. Posteriormente, se aplica el algoritmo de vecinos más cercanos (KNN) para clasificar puntos en dos clases diferentes.
#Three lines to make our compiler able to draw:
import sys
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
x = [2, 3, 8, 7, 6, 12, 14, 9, 11, 13]
y = [18, 16, 20, 15, 14, 22, 20, 19, 18, 18]
classes = [0, 0, 1, 0, 0, 1, 1, 0, 1, 1]
plt.scatter(x, y, c=classes)
plt.show()
#Two lines to make our compiler able to draw:
plt.savefig(sys.stdout.buffer)
sys.stdout.flush()En resumen, este código crea un gráfico de dispersión de puntos bidimensionales y los colorea según su clase. Puedes imaginarte que estos puntos representan datos en un espacio bidimensional, y podríamos querer aplicar el algoritmo KNN para clasificar nuevos puntos basándonos en su proximidad a los existentes en términos de distancia euclidiana. Este es solo el paso inicial, y el código podría extenderse para aplicar el algoritmo KNN y visualizar cómo clasifica nuevos puntos en el conjunto de datos.
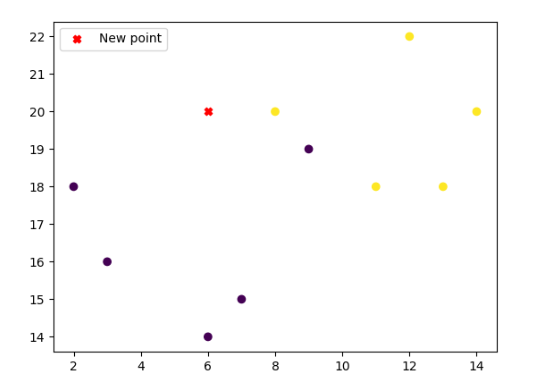
Podemos agregar una utilidad al ejemplo implementando el algoritmo KNN para clasificar un nuevo punto en función de su proximidad a los puntos existentes en el conjunto de datos.
En el siguiente código, hemos introducido un nuevo punto [6, 20] y utilizamos el clasificador KNN para predecir a qué clase pertenece. Luego, visualizamos el conjunto de datos original junto con el nuevo punto y su clasificación predicha. En este caso, el nuevo punto se marca con una «X» y se colorea de rojo.
Esta extensión muestra cómo el algoritmo KNN puede ser utilizado para realizar predicciones sobre nuevos datos en función de su proximidad a los datos existentes en el conjunto de entrenamiento. Este es un ejemplo básico, pero ilustra la idea general de clasificación con KNN.
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt
# Defining data
x = [2, 3, 8, 7, 6, 12, 14, 9, 11, 13]
y = [18, 16, 20, 15, 14, 22, 20, 19, 18, 18]
classes = [0, 0, 1, 0, 0, 1, 1, 0, 1, 1]
# Create KNN classificator
knn_classifier = KNeighborsClassifier(n_neighbors=3)
knn_classifier.fit(np.column_stack((x, y)), classes)
# Define the new point to be classified
new_point = np.array([[6, 20]])
# Classify the new point
predicted_class = knn_classifier.predict(new_point)
print(f"The predicted class for the new point {new_point} is: {predicted_class[0]}")
# Create a scatter plot with the new colored dot
plt.scatter(x, y, c=classes)
plt.scatter(new_point[0, 0], new_point[0, 1], marker='X', c='red', label='New point')
plt.legend()
# Save the graphic as a PNG image
plt.savefig('scatter_plot.png')The predicted class for the new point [[ 6 20]] is: 0Ahí está la predicción! El nuevo punto se ha clasificado como clase 0.
En este código, se ha eliminado la línea plt.show() que mostraba el gráfico directamente. En su lugar, se ha añadido la línea plt.savefig('scatter_plot.png'), que guarda el gráfico como una imagen en formato PNG con el nombre de archivo «scatter_plot.png».
scatter_plot.png
El código está disponible en siguiente enlace de GitHub
Espero que este post te haya resultado de ayuda.
Hasta la próxima.